
More Than Just Code: Rethinking Foundation Models Through the Pathologist’s Eye
Why scaling AI means nothing if it doesn't serve the microscope.

What are foundation models in digital pathology (and why are they changing the game)?

Imagine a visual engine trained not to solve a single problem, but to deeply understand how human tissue looks in all its diversity. That’s essentially what a foundation model is: a deep neural network pretrained on millions of digitized histology image fragments (patches), without requiring specific human labels.
During training, the model doesn’t learn to label—it learns to understand: it recognizes cellular patterns, tissue architecture, staining variations, and differences between organs or diseases. This is done through self-supervised tasks like predicting missing regions, identifying similarities between images, or reconstructing visual content. The result is a feature vector—an embedding—that captures the morphological “meaning” of each image. This embedding becomes the foundation for numerous downstream clinical or research applications.
This deep understanding relies on state-of-the-art architectures:
Vision Transformers (ViT), which process images as sequences of patches and capture long-range spatial relationships. Models like MAE (masked autoencoders) or DINO (contrastive learning) use this structure to generate rich, transferable visual representations.
Deep Convolutional Neural Networks (CNNs) combined with contrastive learning methods, which learn to differentiate between similar and dissimilar images based solely on their visual features, without explicit labels.
Unlike traditional approaches—where a new model must be trained from scratch for each task—foundation models enable smart reuse. With minimal fine-tuning or even by freezing their weights entirely (transfer learning), they can adapt to new tasks using very few labeled examples (few-shot learning), saving significant time, effort, and expert annotation.
This idea isn’t entirely new—it originated from the success of foundation models in natural language processing (like GPT or BERT). But its application to digital pathology has gained momentum in recent years. Here, the input is no longer text but ultra-high-resolution medical images, often gigapixel-scale. The challenge is greater, but so is the potential impact: with a well-trained visual backbone, we can tackle complex tasks like tumor subtyping, mutation prediction, or even multimodal integration with genomics and clinical text.
To achieve this, three key elements are required:
Data: massive and diverse datasets from multiple institutions, populations, and staining techniques.
Models: advanced architectures capable of processing enormous images with contextual attention.
Compute: tens of thousands of GPU hours and strategies to make training more efficient.
And yet, the effort is worth it. A well-designed foundation model can become a cornerstone of the new computational medicine. Since 2020, we’ve seen the emergence of over a dozen such models in pathology alone—marking the beginning of a new era.
Foundation Models that are leading the way
Here are some of the most representative models recently published, showing just how far this new generation of tools in digital pathology can go:
Prov-GigaPath (2024)
A model trained on over 1.3 billion image patches (256×256 px) extracted from 171,189 digital slides from 28 cancer centers.
Its architecture, GigaPath, is specifically designed to process full gigapixel images (WSIs) using dilated attention (LongNet), allowing it to handle tens of thousands of patches per slide.
Results: It achieved state-of-the-art performance in 25 out of 26 clinical and morphological tasks, including subtyping of 9 cancer types and mutation prediction.
Notably, it includes multimodal capabilities, having been trained with pathology report texts as well—enabling zero-shotclassification from clinical descriptions(1).Virchow (2024)
A large-scale foundation model named after the pathologist Rudolf Virchow. Trained on millions of tissue images, it was designed to serve as a robust morphological backbone for pan-cancer tasks.
Results: Achieved an AUC of 0.95 at the specimen level for detecting tumors across 9 common and 7 rare cancers.
What stands out: even with fewer labeled data, it outperformed organ-specific clinical models, demonstrating impressive generalization and label efficiency(2).UNI (2024)
Developed by the Mass General Brigham team, UNI was trained on over 100 million patches and 100,000 WSIs.
Its goal was to create a universal backbone for digital pathology, easily adaptable to a wide range of tasks.
Results: After pretraining, it was successfully adapted to 34 different clinical tasks (cancer, transplants, inflammation), outperforming traditional pathology models in most of them.
A clear example of how a single model can serve as a multi-purpose tool for hospitals and diagnostic labs(3).CONCH (2024)
A multimodal (vision + language) foundation model trained on 1.17 million image-text pairs in pathology.
It integrates histological images with clinical texts (e.g., diagnostic descriptions) using contrastive learning.
Results: Enables natural language clinical queries, tumor segmentation, and rare disease identification by combining visual and textual context.
A powerful demonstration of what’s possible when we break down the silos between imaging and clinical narratives(4).THREADS (2025)
One of the most recent efforts in image + genomics integration. This model aligns histological images (WSIs) with RNA-seq expression profiles and DNA data using a CLIP-like contrastive strategy.
Results: It links tissue morphology with molecular signatures, retrieves images based on genetic profiles, and even generates visual prompts from gene expression data.
Still in early stages, THREADS marks a clear step toward truly multimodal and personalized pathology(5).
With all this evidence, the immediate question we can now answer is the following.
Why foundation models are becoming essential in Digital Pathology?
Digital pathology is undergoing a profound transformation. Every pathology department generates an immense volume of image data. Yet, much of it remains unlabeled, simply because there aren't enough hours (or experts) to annotate it all.
This is where foundation models make a real difference. They offer a new way to leverage the histological big data: learning directly from raw images, without the need for exhaustive labeling. What was once a passive asset—thousands of unannotated files—becomes an active resource. The model digests those images and builds a general morphological understanding that can be reused across diagnostic, prognostic, or exploratory tasks.
Another critical strength lies in their ability to detect subtle patterns. Some foundation models have already shown they can infer molecular alterations (like MSI status) (6) directly from H&E images. Until recently, such insights required immunohistochemistry or genomic testing. This kind of direct inference has major implications: we may soon achieve fully integrative diagnoses based solely on digital histology, without relying on additional assays.
Moreover, these models enable progress toward greater diagnostic standardization. In daily practice, interpretations may vary between pathologists, especially in borderline or complex cases. A foundation model can act as an objective, consistent second opinion highlighting suspicious areas or helping triage cases in high-volume settings, in hospitals facing a shortage of pathology specialists this isn't a luxury it’s a necessity.
From an innovation standpoint, having a ready-to-use foundation model radically accelerates the development of new applications. Previously, every AI pathology project required training a model from scratch, which was slow and often unfeasible due to data limitations. Today, a researcher can build on top of a pretrained model and adapt it to new tasks with only a few labeled examples. This democratizes medical AI: even resource-limited institutions can deploy powerful solutions when they start from a strong foundational base.
"The use of foundation models is essential for histopathological triage, optimizing the pathologist’s workflow."
What We're Starting to Discover Through These Models
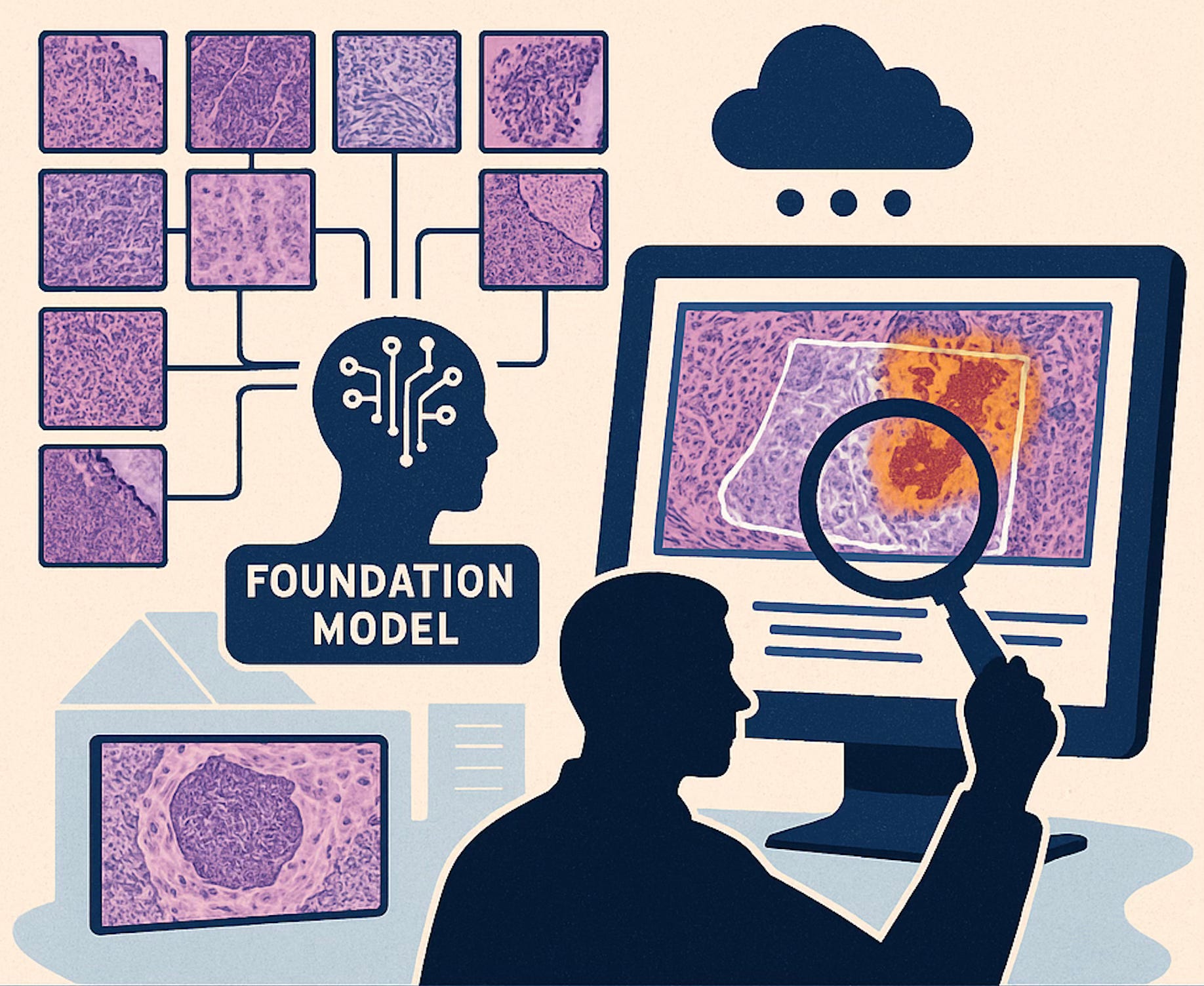
One of the most fascinating aspects of foundation models in digital pathology is not just their technical performance, but the type of knowledge they’re beginning to unlock. For the first time, we have tools capable of analyzing tissue at scale and identifying patterns that escape the human eye (patterns that, as pathologists, we often sensed were there—but had no way to explain or demonstrate). This marks a radical expansion of what we understand as histological diagnosis.
A clear example is the advanced subtyping of complex cancers. Thanks to architectures built to handle gigapixel-scale images, like GigaPath, these models can simultaneously analyze cellular detail and large-scale tissue context. This allows them to detect subtle combinations of patterns that define tumor subtypes with high precision. In some cases, they’ve even outperformed traditional clinical methods—revealing intratumoral heterogeneity that aligns with tumor biology.
We’re also witnessing the emergence of a new class of morphological biomarkers invisible to the human eye. Some foundation models have successfully predicted genetic alterations—such as EGFR mutations—directly from H&E images, without molecular testing (1). What’s striking isn’t just the result, but how they achieve it: by detecting subtle textures and architectural cues that are consistently associated with those alterations. These discoveries open the door to a new kind of pathology—one that infers the molecular from the morphological, dramatically expanding the possibilities of non-invasive diagnosis.
In addition, integrating images with gene expression data or DNA sequencing is generating genotype-phenotype correlations that were previously out of reach (7). Models like THREADS have shown that it’s possible to align visual features with transcriptomic signatures, allowing the discovery of disease subtypes defined not just by how they look, but by their underlying biology. This multimodal approach is redefining how we understand disease—not as fixed categories, but as dynamic spectra with multiple layers of meaning (5).
Taken together, these advances are reshaping the role of the pathologist: from expert observer to interpreter of models that synthesize multiple dimensions of disease. AI does not replace human judgment—but it expands our field of vision, offering a new perspective on what can be seen, measured, and understood within the histological slide.
So... with all the evidence presented, are foundation models the gateway to a new era in pathology?
The answer may be more complex—and more challenging—than what a wave of enthusiasm might suggest. Let me explain why.
Foundation models are not merely revolutionizing the way we analyze pathological images; they are shaping a new paradigm: a pathology practice that is more integrated, equitable, and clinically driven. Far from being just algorithmic tools, these models are laying the groundwork for a more connected form of medicine, where artificial intelligence serves as a true diagnostic copilot—a powerful asset for clinical decision-making.
They are also redefining the human–machine interface in pathology. Systems like CONCH now enable natural language interaction, allowing clinicians to input free-text queries and retrieve matching histological images (4). This not only enhances diagnostic workflows but also supports education and complex decision-making based on subtle visual patterns—another meaningful step forward for clinical utility.
Looking ahead, the future of diagnostics points to greater synergy between multiple data modalities. In this direction, the work by Mao et al. marks a pivotal milestone (8). Their multimodal framework, MIFAPS, integrates MRI, whole-slide images, and clinical data to predict pathological complete response (pCR) to neoadjuvant chemotherapy in breast cancer. Through its hierarchical learning strategy, MIFAPS draws insights from diverse sources—imaging, text, and molecular data—refining both diagnosis and prognosis. This opens the path to multilayered decision-support systems, where the pathologist is no longer presented with an isolated image, but with a context-rich clinical narrative.
However, not everything is glowing when it comes to foundation models. Their deployment presents more than one challenge, and many critical questions remain unanswered.
Technical, Ethical, and Regulatory Challenges
Despite their promise, the development and use of foundation models in pathology face multiple challenges that must be addressed:
Data and technical challenges: Building these models requires massive volumes of high-quality data, yet public pathology datasets remain scarce and heterogeneous (1). For instance, many initial models relied on the TCGA dataset (~30k slides), which, although valuable, does not capture the full real-world variability (different labs, scanners, artifacts) (1). This creates a risk of poor performance when the model encounters samples that deviate from its training distribution. Additionally, annotating pathology data is time-consuming and costly, and self-supervised models must learn without relying on many reliable labels. Another technical hurdle lies in handling gigapixel image sizes: analyzing a whole slide involves processing tens of thousands of patches. Designing architectures that capture both local (cellular) features and global tissue structure is complex. Previous techniques like multiple instance learning (MIL) fragmented the image, losing global context. Only recently have more refined solutions emerged (e.g., hierarchical transformers such as HIPT or the dilated LongNet from GigaPath) (1) to model long-range relationships across a slide. These models also require enormous computational resources (GPUs, TPUs) for training and deployment, which may be prohibitive outside major research centers (1).
Robustness and bias: A critical concern is ensuring that the model learns biologically meaningful features rather than spurious correlations. Recent studies have shown that many current foundation models absorb biases from medical centers or staining protocols(9). For example, models often cluster slides by their hospital of origin rather than tumor type. In some tests, lab-specific “signatures” (staining, scanner, preparation differences) outweighed real biological differences, limiting generalization. Among ten evaluated models, nearly all strongly encoded center-specific features, and only one showed slightly more focus on biological traits than on these confounders (9). This sensitivity to non-clinical variations introduces risks when deploying models in new hospitals. Addressing these biases will require robust color normalization, multi-center federated training, or new robustness metrics (such as the robustness index proposed in that study) to ensure morphological features prevail over origin artifacts. There is also the broader concern of training data fairness: if certain populations or pathologies are underrepresented, the model may underperform in those cases, reproducing health disparities. Data equity and diversity are thus essential to prevent the AI from perpetuating errors or unintended discrimination (9).
Interpretability and trust: Deep learning models are often black boxes, learning complex patterns that are not easily interpretable. In pathology, where diagnostic decisions carry high impact, interpretability is crucial. Pathologists need to understand why the model suggests a certain classification or biomarker. To address this, explainable AI techniques are being used, such as saliency maps highlighting key cellular regions or feature attribution methods, to foster user trust (10). Without explanations, clinicians are unlikely to accept model outputs in practice. Encouragingly, many teams are now integrating mechanisms that highlight slide regions supporting predictions (e.g., tumor areas for a cancer detection). However, producing explanations that are both comprehensible and consistent remains a work in progress. Expert validation is still needed to ensure the model focuses on known pathological features rather than artifacts (11). Only with transparent models can clinical acceptance become a reality.
Data privacy and usage: Foundation models thrive on large, diverse datasets, often requiring data from multiple institutions. This clashes with privacy regulations surrounding sensitive health data. Sharing patient slides across centers is complex. In response, strategies like federated learning and swarm learning are being explored, enabling decentralized training without moving the data. While these approaches preserve patient confidentiality, they add complexity and require strong institutional collaboration. Questions of data ownership also arise: who is accountable if a model trained on multicenter data makes an error? How can informed consent be ensured for the use of millions of retrospective slides, some containing potential identifiers? These are real ethical and legal challenges when building such massive datasets (10).
Regulation and clinical validation: From a regulatory standpoint, foundation models pose a unique dilemma. Agencies like the FDA or EMA typically approve software or devices for specific use cases, based on proven safety and efficacy. By contrast, foundation models are general-purpose by design, adaptable to multiple tasks, making it difficult to pin them down to a single clinical indication. To date, no foundation model has received formal approval for routine diagnostic use. The first AI system in pathology approved by the FDA (in 2021) was a more traditional algorithm focused on detecting metastases in specific lymph nodes—not a multipurpose model (1). For these models to reach patients, rigorous clinical validation is required (ideally through prospective, multicenter studies) to demonstrate their benefit over current standards without compromising safety. This is a major logistical and financial hurdle. Moreover, regulatory frameworks may need to evolve: procedures for model training traceability and post-market monitoring might be required, especially if the model continues to learn or adapt to new data. Ethical questions around liability also emerge: in the event of a diagnostic error, who is responsible—the developer, the hospital, or the algorithm itself? Ultimately, navigating these regulatory and ethical barriers requires close dialogue between technologists, clinicians, and authorities to ensure safe and effective deployment.
Barriers to Clinical Integration
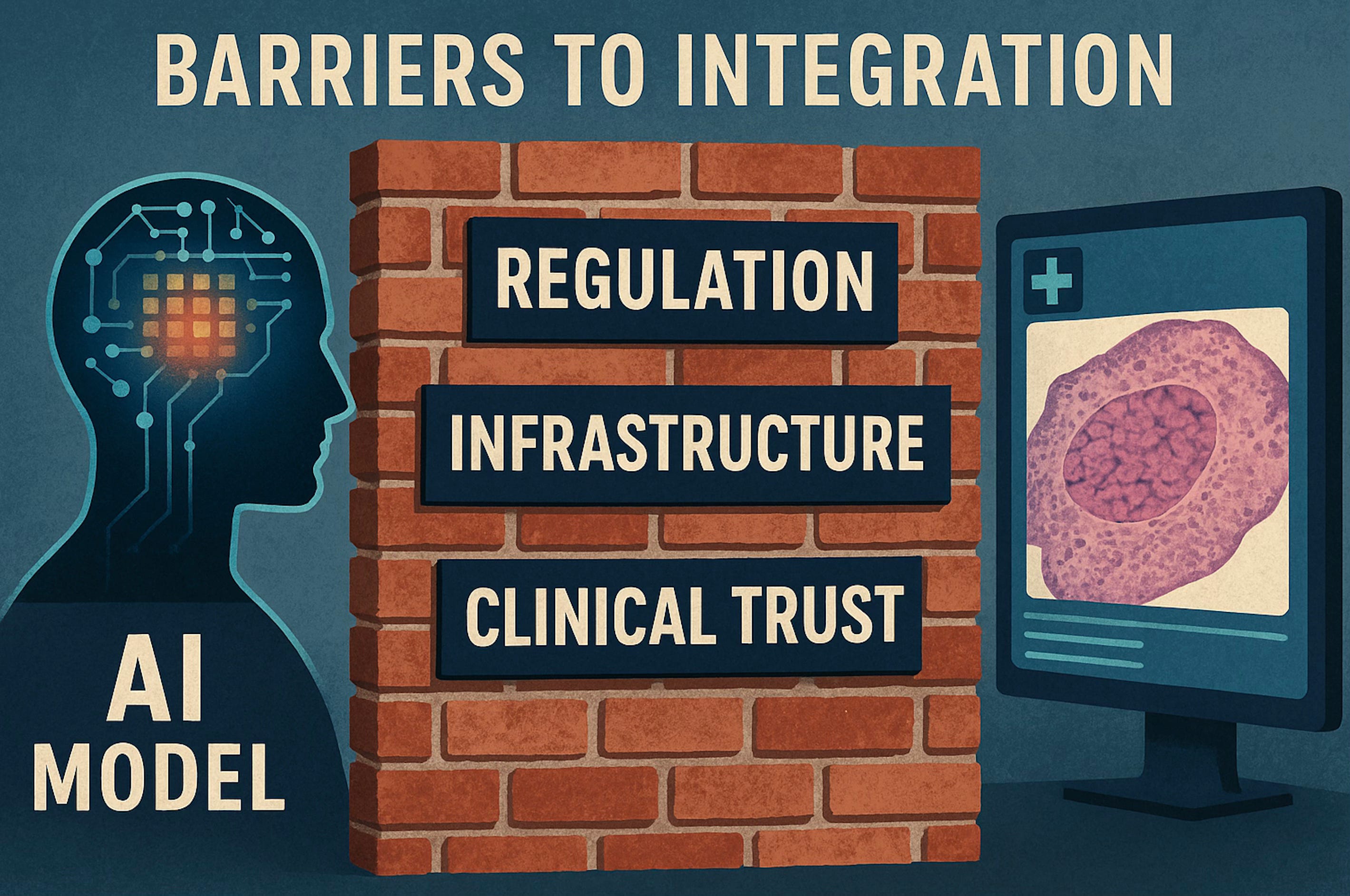
Despite promising research results, these models have yet to become part of the daily workflow in pathology laboratories. Several barriers help explain this gap between innovation and clinical practice:
Insufficient digital infrastructure: A prerequisite for using vision-based models in pathology is digital pathology—that is, routinely scanned slides. However, few institutions are fully digitized in anatomical pathology due to cultural challenges (resistance to shifting from optical microscopy to screens) and technical ones (scanner costs, massive image storage requirements) (12). Many laboratories still rely mainly on glass slides and microscopes, preventing the integration of any AI model. This lack of digital adoption—considered the “silent revolution” required—is a fundamental obstacle for any advanced AI tool.
Lack of clinical validation and real-world evidence: Most foundation models have been evaluated using retrospective studies or research datasets. There are still no prospective clinical trials showing improvements in diagnosis or patient outcomes when using them. As a result, clinicians and institutions remain reluctant to adopt these tools without robust, independent validation that guarantees reliability in real-life cases (12). Furthermore, there is often little evidence on workflow impact (Do they actually save time? Do they improve diagnostic accuracy?), which is critical to convince both clinicians and administrators. This lack of clinical evidence keeps foundation models in an experimental phase.
Lack of regulatory approval: Closely tied to the above, no foundation model in pathology has yet received formal regulatory approval for diagnostic use. Clinical deployment of an AI tool requires regulatory authorization (e.g., FDA in the U.S. or CE marking in Europe), which demands a dossier with clinical performance data. Until these models undergo such a rigorous process, they cannot be routinely used on patients. This creates a vicious circle: without approval they are not used clinically, and without clinical use, it’s hard to obtain real-world evidence to gain approval. Today, integration is limited to pilot projects or investigational use in leading centers—not everyday practice in most hospitals.
Cost and operational viability: Implementing these models can require significant resources. Scanning all slides (equipment, maintenance, staff) is expensive, and many institutions have not budgeted for it (additionally, in several healthcare systems, there is still no reimbursement for AI use in diagnostics) (12). Moreover, running a foundation model may demand accelerated hardware (GPUs/servers) and robust IT infrastructure to handle large volumes of data—implying substantial IT investment. Without clear financial incentives or reimbursement from insurers or national systems, hospitals have little motivation to adopt these technologies. In short, the lack of funding and business models hinders the transition from lab to clinic.
Integration with existing systems and workflows: On a practical level, embedding an AI model into the pathology lab workflow is complex. Pathologists use Laboratory Information Systems (LIS) and image viewers. Integrating an algorithm requires that these systems communicate with the AI tool—ideally seamlessly. Currently, many commercial AI solutions operate in the cloud with proprietary viewers, making it difficult to incorporate them into existing hospital environments (12). On the other hand, research models, even if available, are often not “ready” for deployment: they may require coding skills, lack user-friendly interfaces, or be unvalidated for a specific hospital setting. Thus, even if willing, a typical pathology department has no easy way to “connect” AI to its workflow without developing a specific integration project. Recent initiatives propose standardized frameworks (based on HL7 protocols, open APIs, etc.) to simplify this integration(12), but their adoption remains limited. Until the “last mile” is resolved—bringing model predictions to the pathologist’s desktop in a simple, interoperable, real-time manner—AI will remain confined to research.
Human and organizational factors: Resistance to change in clinical environments should not be underestimated. The introduction of AI systems may cause distrust or concern among pathologists, who may feel their autonomy is threatened or be wary of a “black-box” algorithm. If staff are unconvinced of the utility or feel it adds burden (e.g., having to verify unreliable outputs), adoption will fail. Institutional culture also plays a role: some pioneering labs embrace innovation, others are more conservative and require broad consensus before implementing new tools. Additionally, lack of training is a barrier—few pathologists are trained in AI, so education is needed to interpret outputs from foundation models. Clinical champions who advocate for the technology and demonstrate its value in concrete cases can help overcome inertia—but this takes time. In summary, earning the trust and acceptance of medical staff is just as critical as solving technical challenges. Implementation must clearly demonstrate that the foundation model supports and enhances diagnosis, rather than obstructing it or unjustifiably replacing the pathologist.
Taken together, these factors explain why, as of June 2025, foundation models in pathology—despite their enormous potential—have not yet been incorporated into routine clinical practice. The community is working to close this gap by developing open integration frameworks and generating clinical evidence, but time, investment, and multidisciplinary efforts will be required to overcome the technological, regulatory, and human barriers described above(12).
Performance vs. Expectations: Recent Critical Evaluations
Although foundation models have generated enormous excitement, it is important to critically assess whether their current performance lives up to the hype. Recent studies offer a more sober evaluation:
“Generalist” models vs. specialized models? Researchers at the Mayo Clinic compared vision-language foundation models (derived from CLIP and trained on general data) with simpler models trained on curated pathology datasets (e.g., KimiaNet or a self-supervised ResNet trained on TCGA). Surprisingly, the non-foundational, domain-specific models outperformed the general-purpose foundation models in several classification and retrieval tasks(11). For instance, DinoSSLPath (a colorectal cancer–specific model) achieved better F1 scores in retrieving colon and liver images than massively trained foundation models(11). KimiaNet outperformed the foundation models in identifying certain breast and skin pathologies. These findings suggest that, for now, a large general-purpose model does not automatically guarantee better performance than a smaller model well trained on relevant data. The quality and relevance of training data remains critical. The authors argue that while foundation models are promising, they must be refined and fed with expertly annotated medical datasets to truly shine. Without this foundation, generalist models may fall short compared to more focused approaches(11).
Robustness and generalization under scrutiny: As discussed earlier, a 2025 analysis questioned whether foundation models had truly learned universal biological features from pathology images—or whether they were “cheating” by relying on spurious cues (origin center, staining batch). The findings were sobering: nearly all evaluated models exhibited strong center-specific bias, organizing their internal representations more by lab of origin than by cancer type(9). Even in classification tasks, many errors stemmed from confusion with tumors from the same institution, highlighting dependence on institutional artifacts. Only one out of ten models had a robustness index greater than 1, indicating even a slight predominance of biological features over institutional ones. Embedding space visualizations further confirmed this: representations clustered more by source than by diagnosis. In short, these critical results show that current foundation models are not as invariant or context-agnostic as expected, which is a wake-up call. To fulfill their promise of generalization, they must improve robustness, likely through training on more diverse data and using strategies to minimize confounding. Until then, their impressive metrics may not translate into reliable performance when deployed in institutions different from those used in training.
Expectations vs. real-world performance: In practice, some early attempts to implement AI into clinical workflows have revealed the gap between paper-level performance and real-world utility. A model may achieve high AUC in detecting a specific cancer, but if it generates too many false positives or its outputs are difficult to interpret in routine use, pathologists tend to ignore it. There are also tasks where AI was expected to uncover novel prognostic patterns. However, in several studies, foundation models mainly identified already-known features (e.g., tumor grade, lymphocyte density) correlated with survival, rather than discovering entirely new biomarkers. This does not diminish their value—but it tempers expectations: these tools may end up reinforcing and quantifying classic pathological criteria rather than revolutionizing our understanding of disease overnight. Similarly, the idea that a single foundation model could solve countless tasks with minimal tuning has been challenged. In practice, these models often require fine-tuning for each application, and performance varies widely across tasks. In short, although the overall trend is positive, we must avoid naïve optimism. The scientific community is now subjecting these models to rigorous testing—a healthy process that helps identify the areas where they truly offer breakthroughs and those where improvement is still needed.
A critical perspective in the literature: Several reviews and editorials advocate for a balanced assessment. A recent editorial in J. Clin. Pathology highlighted the disruptive potential of foundation models, but also emphasized persistent challenges in scalability, bias, and clinical integration (10). Similarly, Annals of Oncology (2025) noted that although the "AI era" in pathology has arrived, these tools have yet to fully meet the high expectations of precision oncology (13). The authors stress the need for rigorous validation, interpretability, and multidisciplinary collaboration to turn promise into clinical reality. In summary, the emerging consensus in the literature is one of moderated enthusiasm: foundation models indeed have transformative potential, but the hard work of ensuring their reliability, fairness, and clinical utility is still underway. Today’s constructive critiques will help guide the next generation of improvements—so that, in the near future, these powerful AI systems can achieve their intended performance and benefit both patients and pathologists alike.
Towards a realistic and human-centered implementation of foundation models in pathology
After reviewing the promises, technical challenges, and clinical barriers, one conclusion stands out: foundation models don’t need more hype—they need direction, clinical validation, and a deeply human integration strategy.
Solutions will not emerge from technical brilliance alone, but from a vision that connects science, clinical practice, and systemic transformation. That’s where true change begins.
Redesign clinical validation
We must move beyond conventional metrics (AUC, F1). Multicenter studies are needed to measure real-world impact: fewer diagnostic errors, faster turnaround times, improved workflow efficiency. What matters is clinical usefulness, not just algorithmic accuracy.Build joint consortia with hospitals
Integration cannot be imposed—it must be co-created. Models should be trained and tested within real-life clinical settings, under direct medical supervision, reflecting the diversity of institutional contexts. Clinical trust is earned, not assumed.Design with the pathologist at the center
The best tools are not the most complex—they are the ones that disappear into the workflow. Integration isn’t about more interfaces, but about AI flowing seamlessly and precisely where medical judgment needs it.Educate to understand, not to replace
Sustainable implementation demands education. It’s not just about using the tool—it’s about reading it, interpreting it, challenging it. Only then can AI become a co-pilot with judgment, not an untouchable black box.Design with ethics, validate with diversity
Without representative data, progress is fragile. Diagnostic equity must be embedded in the design, not added to the discourse. For that, we need transparency, traceability, and clinical voices involved from the beginning.
Foundation models should not be delivered as sealed products to clinicians—but as living systems, co-designed with them.
Turning medical AI into a legitimate, useful, and trustworthy clinical tool is not just a technical challenge. It is a matter of leadership, shared language, and vision.
And that journey is only just beginning.
References:
Xu H, Usuyama N, Bagga J, Zhang S, Rao R, Naumann T, et al. A whole-slide foundation model for digital pathology from real-world data. Nature. 2024 Jun;630(8015):181–8.
Vorontsov E, Bozkurt A, Casson A, Shaikovski G, Zelechowski M, Severson K, et al. A foundation model for clinical-grade computational pathology and rare cancers detection. Nat Med. 2024 Oct;30(10):2924–35.
Chen RJ, Ding T, Lu MY, Williamson DFK, Jaume G, Song AH, et al. Towards a general-purpose foundation model for computational pathology. Nat Med. 2024 Mar;30(3):850–62.
Lu MY, Chen B, Williamson DFK, Chen RJ, Liang I, Ding T, et al. A visual-language foundation model for computational pathology. Nat Med. 2024 Mar;30(3):863–74.
Vaidya A, Zhang A, Jaume G, Song AH, Ding T, Wagner SJ, et al. Molecular-driven Foundation Model for Oncologic Pathology [Internet]. arXiv; 2025 [cited 2025 Jun 27]. Available from: http://arxiv.org/abs/2501.16652
Wang X, Zhao J, Marostica E, Yuan W, Jin J, Zhang J, et al. A pathology foundation model for cancer diagnosis and prognosis prediction. Nature. 2024 Oct;634(8035):970–8.
ar5iv [Internet]. [cited 2025 Jun 27]. Multi-Modal Foundation Models for Computational Pathology: A Survey. Available from: https://ar5iv.labs.arxiv.org/html/2503.09091
Mao N, Dai Y, Zhou H, Lin F, Zheng T, Li Z, et al. A multimodal and fully automated system for prediction of pathological complete response to neoadjuvant chemotherapy in breast cancer. Science Advances. 2025 Apr 30;11(18):eadr1576.
Jong ED de, Marcus E, Teuwen J. Current Pathology Foundation Models are unrobust to Medical Center Differences [Internet]. arXiv; 2025 [cited 2025 Jun 27]. Available from: http://arxiv.org/abs/2501.18055
Hacking S. Foundation models in pathology: bridging AI innovation and clinical practice. Journal of Clinical Pathology. 2025 Jul 1;78(7):433–5.
Alfasly S, Nejat P, Hemati S, Khan J, Lahr I, Alsaafin A, et al. Foundation Models for Histopathology—Fanfare or Flair. Mayo Clinic Proceedings: Digital Health. 2024 Mar 1;2(1):165–74.
Angeloni M, Rizzi D, Schoen S, Caputo A, Merolla F, Hartmann A, et al. Closing the gap in the clinical adoption of computational pathology: a standardized, open-source framework to integrate deep-learning models into the laboratory information system. Genome Medicine. 2025 May 26;17(1):60.
Marra A, Morganti S, Pareja F, Campanella G, Bibeau F, Fuchs T, et al. Artificial intelligence entering the pathology arena in oncology: current applications and future perspectives. Annals of Oncology. 2025 Jul 1;36(7):712–25.